网络基础
TCP
简述
- 面向连接的
- 可靠的传输协议
浏览器访问 www.baidu.com 的过程
- 浏览器向DNS服务器发出解析域名的请求;
- DNS服务器将”www.baidu.com"域名解析为对应的IP地址,并返回给浏览器;
- 浏览器与百度服务器进行三次握手,建立TCP连接;
- 浏览器发出HTTP请求报文;
- 服务器回复HTTP响应报文;
- 浏览器解析响应报文,渲染HTML内容,并显示在页面上;
- 收发报文结束,释放TCP连接,执行四次挥手。
TCP三次握手 建立连接
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接.
第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
SYN:同步序列编号(Synchronize Sequence Numbers)
第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。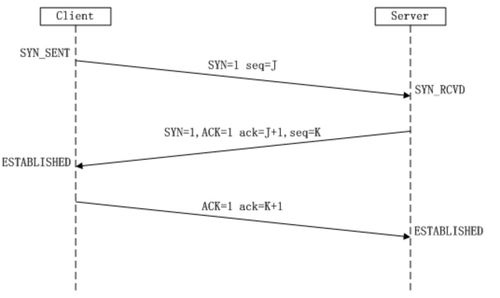
TCP四次挥手
1.第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
2.第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
3.第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
4.第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1, Server进入CLOSED状态,完成四次挥手。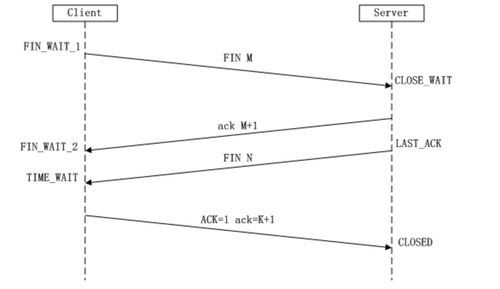
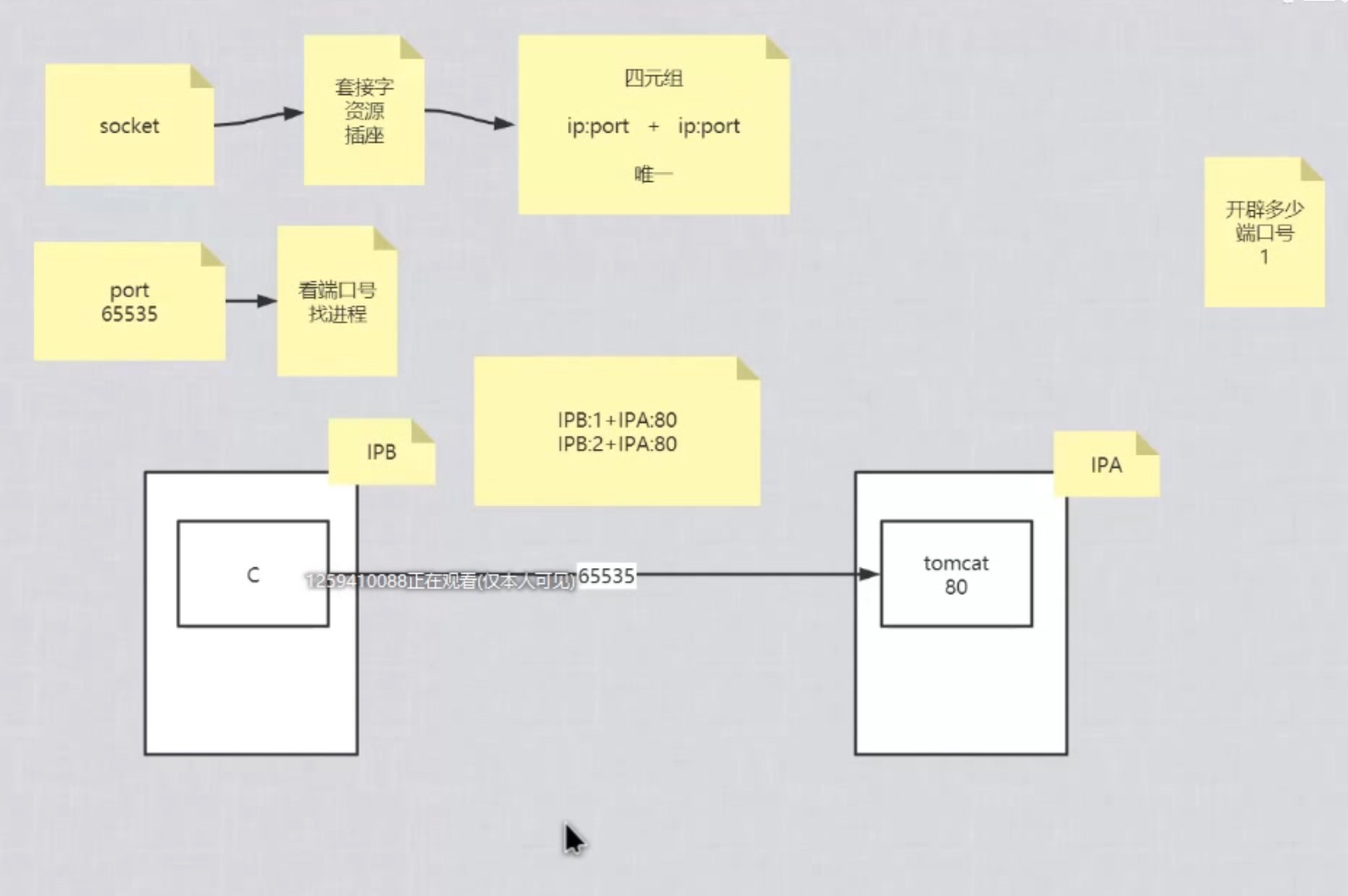
SOCKET
TCP滑动窗口
滑动窗口
tcp通过滑动窗口进行流量控制,所谓的窗口可以理解为接收端所能提供的缓冲区大小。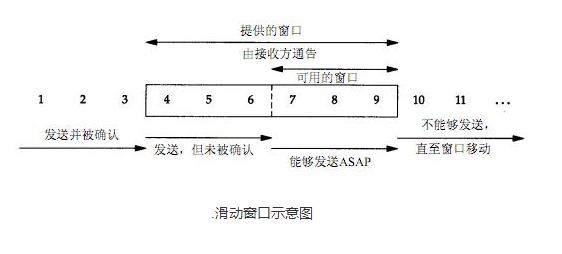
TCP是一个滑动窗口协议,即一个TCP连接的发送端在某个时刻能发多少数据是由滑动窗口控制的
滑动窗口示意图
RTT(Round trip time)
表示从发送端到接收端的一去一回需要的时间。
TCP在数据传输过程中会对RTT进行采样(即对发送的数据包及其ACK的时间差进行测量,并根据测量值更新RTT值)
RTO (Retransmission TimeOut)
发送数据包,启动重传定时器,重传定时器到期所花费的时间
TCP根据得到的RTT值更新RTO值,即Retransmission TimeOut,就是重传间隔,发送端对每个发出的数据包进行计时,如果在RTO时间内没有收到所发出的数据包的对应ACK,则任务数据包丢失,将重传数据。一般RTO值都比采样得到的RTT值要大。
在面对未知的流量暴增,可以预先怎么处理
大致为以下两种情况
1. 不可预测流量(网站被恶意刷量;CDN回源抓取数据;合作业务平台调取平台数据等)
2. 可预测流量(突然爆发的社会热点,营销活动的宣传;)
防止流量暴涨的预备方案
- 通过压测,进行流量预估,流量基本上要在压测结果,压测得到的结果要达到设计流量 * 3(*4, * 5都可以)
- 降级方案,需要考虑业务场景,采用不同的降级方案,不能随意在业务主流程进行
- 限流方案:计数器、滑动窗口、漏桶
计数器
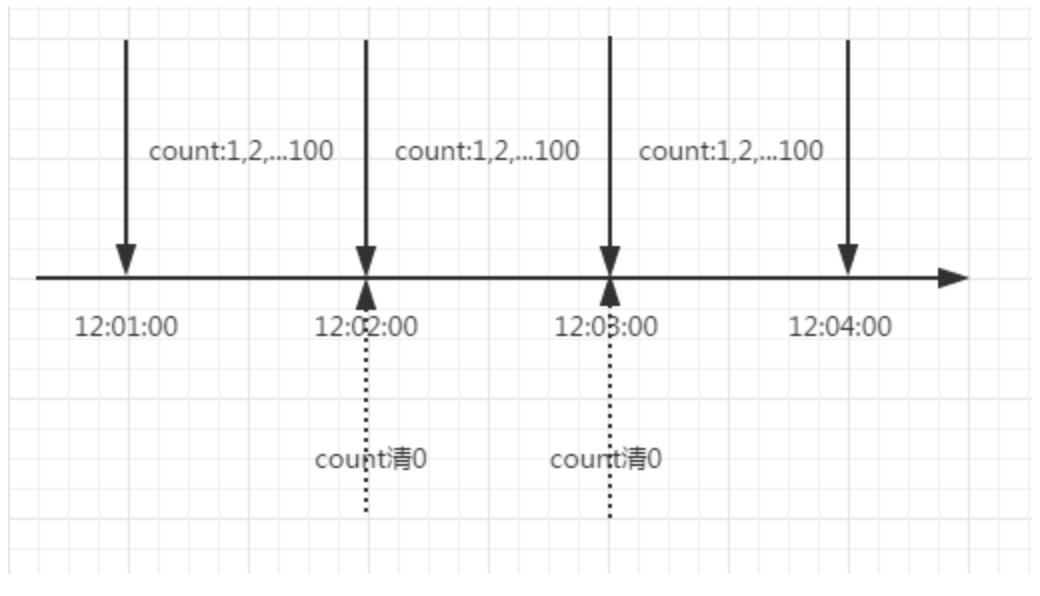
计数器是一种比较简单的限流算法,用途比较广泛,在接口层面,很多地方使用这种方式限流。在一段时间内,进行计数,与阀值进行比较,到了时间临界点,将计数器清0。
局限性:
这里需要注意的是,存在一个时间临界点的问题。举个栗子,在12:01:00到12:01:58这段时间内没有用户请求,然后在12:01:59这一瞬时发出100个请求,OK,然后在12:02:00这一瞬时又发出了100个请求。这里你应该能感受到,在这个临界点可能会承受恶意用户的大量请求,甚至超出系统预期的承受。
滑动窗口
由于计数器存在临界点缺陷,后来出现了滑动窗口算法来解决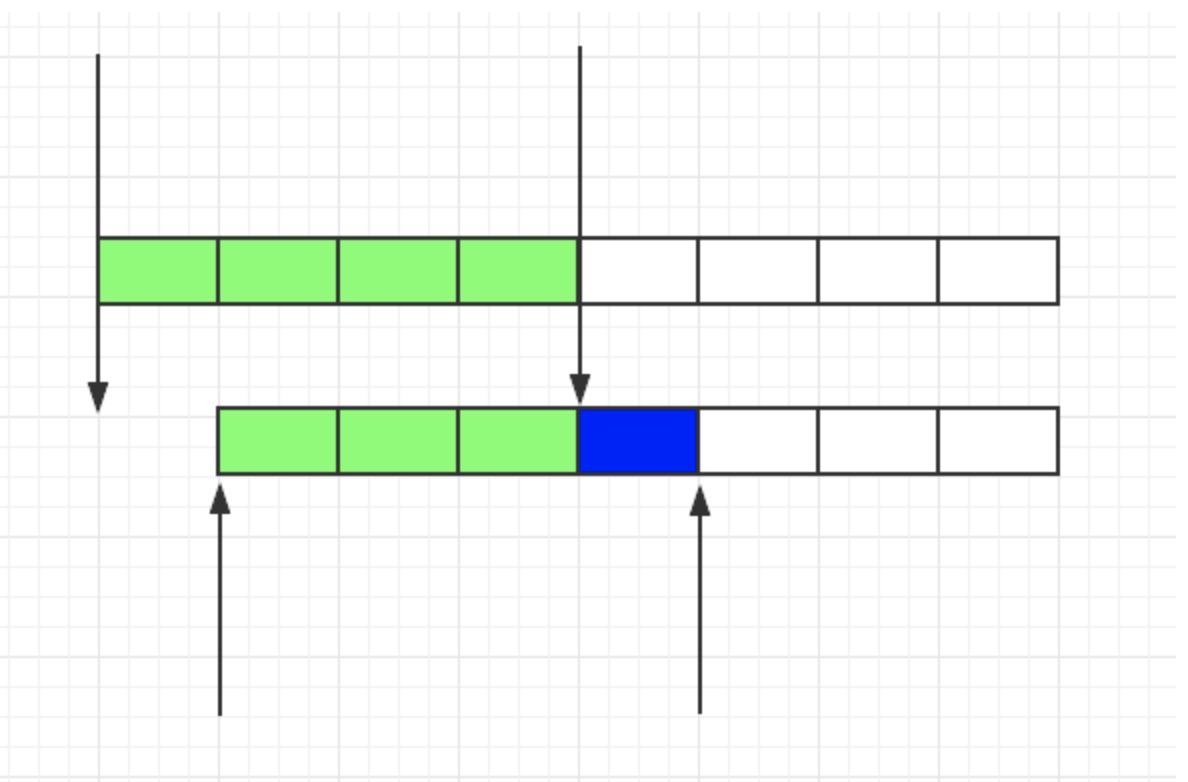
局限性:
滑动窗口的意思是说把固定时间片,进行划分,并且随着时间的流逝,进行移动,这样就巧妙的避开了计数器的临界点问题。也就是说这些固定数量的可以移动的格子,将会进行计数判断阀值,因此格子的数量影响着滑动窗口算法的精度
漏桶
虽然滑动窗口有效避免了时间临界点的问题,但是依然有时间片的概念,而漏桶算法在这方面比滑动窗口而言,更加先进。
有一个固定的桶,进水的速率是不确定的,但是出水的速率是恒定的,当水满的时候是会溢出的。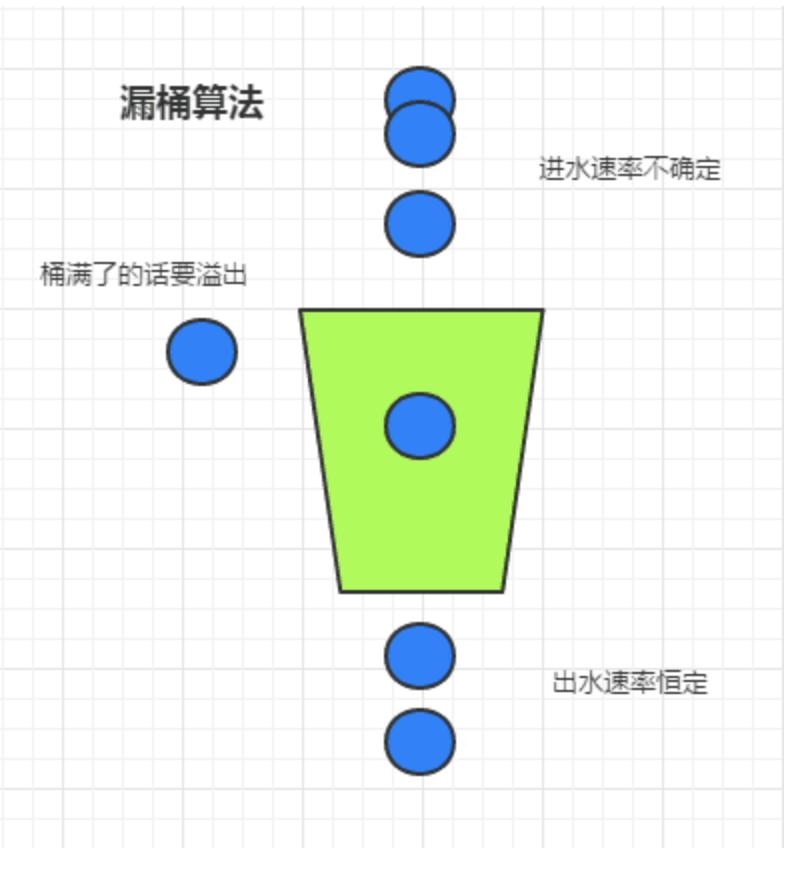
局限性:
生成令牌的速度是恒定的,而请求去拿令牌是没有速度限制的。这意味,面对瞬时大流量,该算法可以在短时间内请求拿到大量令牌,而且拿令牌的过程并不是消耗很大的事情。(有一点生产令牌,消费令牌的意味)
不论是对于令牌桶拿不到令牌被拒绝,还是漏桶的水满了溢出,都是为了保证大部分流量的正常使用,而牺牲掉了少部分流量,这是合理的,如果因为极少部分流量需要保证的话,那么就可能导致系统达到极限而挂掉,得不偿失。
IO 多路复用
同步阻塞
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
Select、Poll与Epoll区别
| \ | select | poll | epoll |
|---|---|---|---|
| 支持最大连接数 | 1024(x86) or 2048(x64) | 无上限 | 无上限 |
| IO效率 | 每次调用进行线性遍历,时间复杂度为O(N) | 每次调用进行线性遍历,时间复杂度为O(N) | 使用“事件”通知方式,每当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到rdllist里面,这样epoll_wait返回的时候我们就拿到了就绪的fd。时间发复杂度O(1) |
| fd拷贝 | 每次select都拷贝 | 每次poll都拷贝 | 调用epoll_ctl时拷贝进内核并由内核保存,之后每次epoll_wait不拷贝 |
Linux IO模型
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。
常见的IO模型有阻塞、非阻塞、IO多路复用,异步
同步阻塞IO
同步阻塞 IO 模型是最常用的一个模型,也是最简单的模型。在linux中,默认情况下所有的socket都是blocking。它符合人们最常见的思考逻辑。阻塞就是进程 “被” 休息, CPU处理其它进程去了。
同步非堵塞IO
同步非阻塞就是 “每隔一会儿瞄一眼进度条” 的轮询(polling)方式。
对比同步阻塞IO
优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
进程
一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。
线程
进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。
与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
进程与线程的区别总结
线程具有许多传统进程所具有的特征,故又称为轻型进程(Light—Weight Process)或进程元;而把传统的进程称为重型进程(Heavy—Weight Process),它相当于只有一个线程的任务。在引入了线程的操作系统中,通常一个进程都有若干个线程,至少包含一个线程。
根本区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
CPU密集型和IO密集型
CPU密集型
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作CPU读写IO(硬盘/内存)时,IO可以在很短的时间内完成,而CPU还有许多运算要处理,因此,CPU负载很高。
CPU密集表示该任务需要大量的运算,而没有阻塞,CPU一直全速运行。CPU密集任务只有在真正的多核CPU上才可能得到加速(通过多线程),而在单核CPU上,无论你开几个模拟的多线程该任务都不可能得到加速,因为CPU总的运算能力就只有这么多。
CPU使用率较高(例如:计算圆周率、对视频进行高清解码、矩阵运算等情况)的情况下,通常,线程数只需要设置为CPU核心数的线程个数就可以了。 这一情况多出现在一些业务复杂的计算和逻辑处理过程中。比如说,现在的一些机器学习和深度学习的模型训练和推理任务,包含了大量的矩阵运算。
IO密集型
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等IO (硬盘/内存) 的读写操作,因此,CPU负载并不高。
密集型的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而程序的逻辑做得不是很好,没有充分利用处理器能力。
CPU 使用率较低,程序中会存在大量的 I/O 操作占用时间,导致线程空余时间很多,通常就需要开CPU核心数数倍的线程。
其计算公式为:IO密集型核心线程数 = CPU核数 / (1-阻塞系数)。
当线程进行 I/O 操作 CPU 空闲时,启用其他线程继续使用 CPU,以提高 CPU 的使用率。例如:数据库交互,文件上传下载,网络传输等。
CPU密集型与IO密集型任务的使用说明
当线程等待时间所占比例越高,需要越多线程,启用其他线程继续使用CPU,以此提高CPU的利用率;
当线程CPU时间所占比例越高,需要越少的线程,通常线程数和CPU核数一致即可,这一类型在开发中主要出现在一些计算业务频繁的逻辑中。
CPU密集型任务与IO密集型任务的区别
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数,避免线程或进程的切换。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
IO密集型任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。涉及到网络、磁盘IO的任务都是IO密集型任务,
对于IO密集型任务,线程数越多,CPU效率越高,但也有一个限度。
总结
一个计算为主的应用程序(CPU密集型程序),多线程或多进程跑的时候,可以充分利用起所有的 CPU 核心数,比如说16核的CPU ,开16个线程的时候,可以同时跑16个线程的运算任务,此时是最大效率。但是如果线程数/进程数远远超出 CPU 核心数量,反而会使得任务效率下降,因为频繁的切换线程或进程也是要消耗时间的。因此对于 CPU 密集型的任务来说,线程数/进程数等于 CPU 数是最好的了。
如果是一个磁盘或网络为主的应用程序(IO密集型程序),一个线程处在 IO 等待的时候,另一个线程还可以在 CPU 里面跑,有时候 CPU 闲着没事干,所有的线程都在等着 IO,这时候他们就是同时的了,而单线程的话,此时还是在一个一个等待的。我们都知道IO的速度比
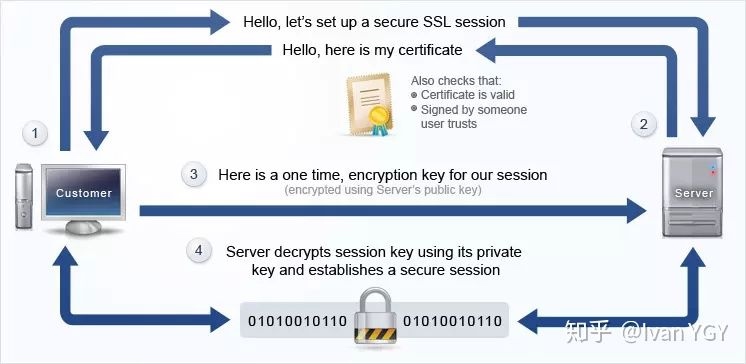
https原理
HTTP与HTTPS有什么区别?
HTTPS和HTTP的区别主要如下:
- https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
- http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
- http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
非对称加密方案
- 某网站服务器拥有公钥A与对应的私钥A’;浏览器拥有公钥B与对应的私钥B’。
- 浏览器把公钥B明文传输给服务器。
- 服务器把公钥A明文给传输浏览器。
- 之后浏览器向服务器传输的内容都用公钥A加密,服务器收到后用私钥A’解密。由于只有服务器拥有私钥A’,所以能保证这条数据的安全。
- 同理,服务器向浏览器传输的内容都用公钥B加密,浏览器收到后用私钥B’解密。同上也可以保证这条数据的安全。
数字签名
数字签名的制作过程:
- CA机构拥有非对称加密的私钥和公钥。
- CA机构对证书明文数据T进行hash。
- 对hash后的值用私钥加密,得到数字签名S。
浏览器验证过程:
- 拿到证书,得到明文T,签名S。
- 用CA机构的公钥对S解密(由于是浏览器信任的机构,所以浏览器保有它的公钥。详情见下文),得到S’。
- 用证书里指明的hash算法对明文T进行hash得到T’。
- 显然通过以上步骤,T’应当等于S‘,除非明文或签名被篡改。所以此时比较S’是否等于T’,等于则表明证书可信。
制作数字签名时需要hash一次?
最显然的是性能问题,前面我们已经说了非对称加密效率较差,证书信息一般较长,比较耗时。而hash后得到的是固定长度的信息(比如用md5算法hash后可以得到固定的128位的值),这样加解密就快很多。
每次进行HTTPS请求时都必须在SSL/TLS层(http的安全层)进行握手传输密钥吗?
服务器会为每个浏览器(或客户端软件)维护一个session ID,在TLS握手阶段传给浏览器,浏览器生成好密钥传给服务器后,服务器会把该密钥存到相应的session ID下,之后浏览器每次请求都会携带session ID,服务器会根据session ID找到相应的密钥并进行解密加密操作,这样就不必要每次重新制作、传输密钥了!
Linux根据文件路径查找索引节点
查找时,会遍历路径的过程中,会逐层地将各个路径组成部分解析成目录项对象。如果此目录项对象在目录项缓存中,则直接从缓存中获取;如果该目录项在缓存中不存在,则进行一次实际的读盘操作,从磁盘中读取该目录项所对应的索引节点。得到索引节点之后,则建立索引节点与该目录项的联系。如此循环,直到找到目标文件对于的目录项,也就找到了索引节点,而由索引节点找到对应的超级块对象,就可知道该文件所在的文件系统的类型。
进程创建时文件的复制与共享
当一个进程系统调用fork()创建一个子进程时,fork()将调用内核函数do_fork()对父进程的进程控制块进行复制,并将这个副本作为子进程的控制块。如果父进程有已经打开的文件,那么子进程理所当然的按某种方式来继承这些文件